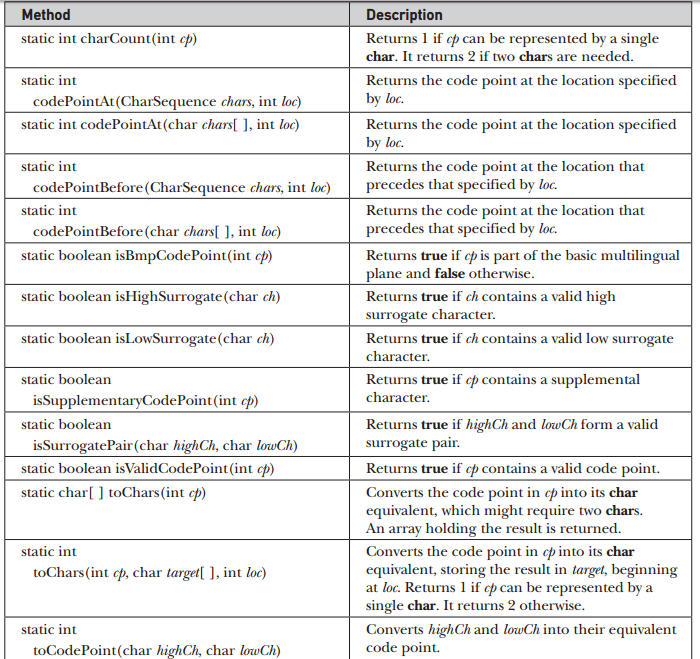
Character
- Character is the wrapper of char which have the following constructor
Character(char ch)
ch specifies the character that will be wrapped by the Character object being created.
To obtain the char valuecontainedin a Character object
char charValue( )
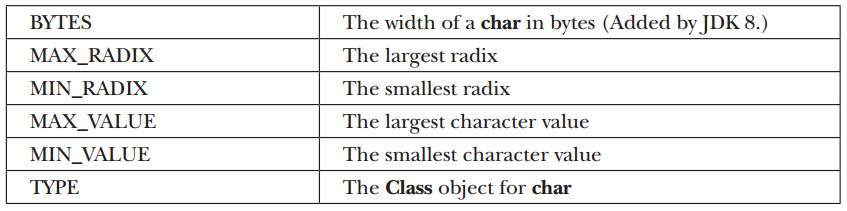
- It defines the following constants as follows:
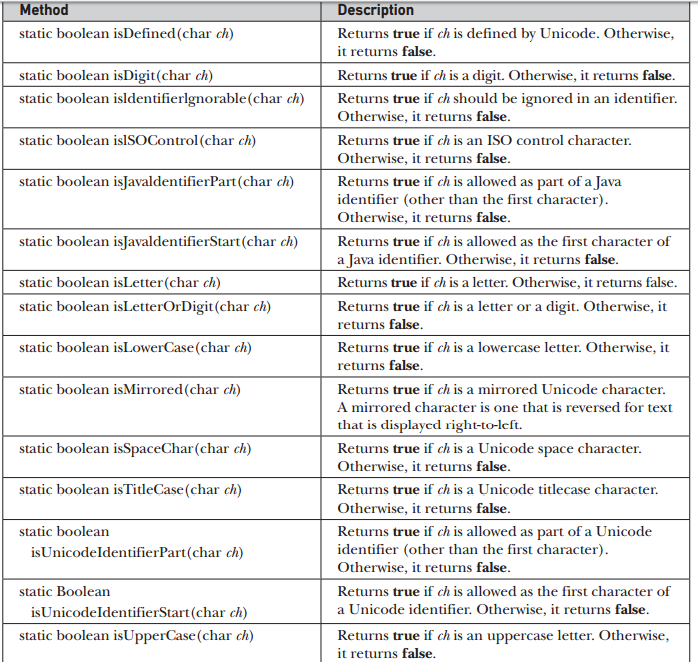
- Character includes several static methods that categorize characters and alter their case.
// Demonstrate several Is... methods.
public class IsDemo
{
public static void main(String args[])
{
char a[] = {'a', 'b', '5', '?', 'A', ' '};
for(int i=0; i<a.length; i++)
{
if(Character.isDigit(a[i]))
System.out.println(a[i] + " is a digit.");
if(Character.isLetter(a[i]))
System.out.println(a[i] + " is a letter.");
if(Character.isWhitespace(a[i]))
System.out.println(a[i] + " is whitespace.");
if(Character.isUpperCase(a[i]))
System.out.println(a[i] + " is uppercase.");
if(Character.isLowerCase(a[i]))
System.out.println(a[i] + " is lowercase.");
}
}
}
Output:
a is a letter.
a is lowercase.
b is a letter.
b is lowercase.
5 is a digit.
A is a letter.
A is uppercase.
is whitespace.
Characterdefines followingmethods
static char forDigit(int num, int radix) //returns the digit character associated with the value of num where the radix specifies the radix of the conversion.
static int digit(char digit, int radix) //returns the integer value associated with the specified character according to the specified radix.
int compareTo(Character c) //returns zero if the invoking object and c have the same value , negative value if the invoking object has a lower value Otherwise, it returns a positive value.
getDirectionality( ) //used to determine the direction of a character by using Several constants.
It also overrides the equals( )and hashCode( )methods.
Two other character-related classes are Character.Subset, used to describe a subset of Unicode, and Character.UnicodeBlock,which contains Unicode character blocks.

Methods added to Character to support for Unicode point
- In the past, all Unicode characters could be held by 16 bits , which is the size of a char because those values ranged from 0 to FFFF.
As the Unicode character set has been expanded from 0 to 10FFFF which caused a fundamental problem for Java,Beginning with JDK 5, the Character class has included support for 32-bit Unicode characters.
code point is a character in the range 0 to 10FFFF.
supplemental characters are the characters whose value is greater than FFFF.
The basic multilingual plane (BMP) are those characters between 0 and FFFF.
A supplemental character has a value greater than a char can hold, some means of handling the supplemental characters was needed. Java addressed this problem in two ways.
Java uses two chars to represent a supplemental character. The first char is called the high surrogate, and the second is called the low surrogate. New methods, such as codePointAt( ), were provided to translate between code points and supplemental characters.
Java overloaded several preexisting methods in the Character class. These forms uses int rather then char data because an int is large enough to hold any character as a single value, it can be used to store any character.
Examples:
static boolean isDigit(int cp)
static boolean isLetter(int cp)
static int toLowerCase(int cp)
In addition to these methods Character also provides the following methods to support for code points.